To test or not to test
This is an excerpt from my book Street Coder, prepared by Christopher Kaufmann from Manning Publications.

How can you keep your code reliable without testing?
Take 40% off Street Coder by entering fcckapanoglu into the discount code box at checkout at manning.com.
Don’t write tests
Yes, testing is helpful, but nothing is better than avoiding writing tests completely. How do you get away without writing tests and still keep your code reliable?
Don’t write code
If a piece of code doesn’t exist, it doesn’t need to be tested either. Deleted code has no bugs. Think about this when writing code. Is that something worth writing tests for? Maybe you don’t need to write that code at all. Can you opt for using an existing package over implementing it from scratch? Can you use an existing class that does the exact same thing you’re trying to implement? For example, you might be tempted to write custom regular expressions for validating URLs when all you need to do is use System.Uri class.
Third-party code isn’t guaranteed to be perfect or always suitable for your purposes. You might later discover that the code doesn’t work for you. It’s usually worth taking that risk before trying to write something from scratch. Similarly, the same codebase you’re working on might have the code doing the same job implemented by a colleague. Search your code base to see if something is there.
If nothing works, be ready to implement your own. Don’t be scared of reinventing the wheel; it can be educational.
Don’t write all the tests
The famous Pareto principle states that eighty percent of consequences are the results of twenty percent of the causes. At least, this is what eighty percent of the definitions say. It’s more commonly called the 80/20 principle. It’s applicable in testing too. You can get eighty percent reliability from twenty percent test coverage if you choose your tests wisely.
Bugs don’t appear homogenously. Not every code line has the same probability of producing a bug. It’s more likely to find bugs in more commonly used code, and code with high churn. You can call those areas of the code hot paths where a problem is more likely to happen.
This is exactly what I did with my web site. It had no tests whatsoever even after it became one of the most popular Turkish web sites in the world. Then, I had to add tests because too many bugs started to appear with the text markup parser. The markup was custom, it barely resembled Markdown, but I developed it before Markdown was even a vitamin in the oranges Dave Gruber ate. Because parsing logic was complicated and prone to bugs, it became economically infeasible to fix every issue after deploying to production. I developed a test suite for it. That was before the advent of test frameworks, and I had to develop my own. I incrementally added more tests as more bugs appeared, because I hated creating the same bugs, and we developed a quite extensive test suite later, which saved us thousands of failing production deployments. Tests just work.
Even navigating to your web site’s home page in a browser provides a good amount of code coverage because it exercises many shared code paths with other pages. This is called smoke testing. It comes from the times when they developed the first prototype of the computer and tried to turn it on to see if smoke came out of it. If there was no smoke, that was pretty much a good sign. Similarly, having good test coverage for critical, shared components is more important than having one hundred percent code coverage. Don’t spend hours to add test coverage to that missing line in the constructor of a class if it won’t make much difference. You already know that code coverage isn’t the whole story.
Let the compiler test your code
With a strongly-typed language, you can use the type system to reduce the number of test cases needed. We already discussed how nullable references can help you to avoid null checks in the code, which also reduces the need to write tests for null cases. Let’s go over a simple example. We need to validate if a chosen username is valid, and we need a function that validates usernames.
Eliminate null checks
Let our rule for a username be lowercase alphanumeric characters up to eight characters long. A regular expression pattern for such a username is “ ^[a-z0–9]{1,8}$”. We can write a username class as in listing 1. We define a Username class to represent all usernames in the code. We avoid the need to think about where we should validate our input by passing this to any code that requires a username.
In order to make sure that a username is never invalid, we validate the parameter in the constructor and throw an exception if it’s not in the correct format. Apart from the constructor, the rest of the code is boilerplate to make it work in comparison scenarios. Remember, you can always derive such a class by creating a base StringValue class and write minimal code for each string-based value class. I wanted these to remain here to be explicit about what the code entails.
Listing 1 A username value type implementation
#A We validate the username here, once and for all.
#B Our usual boilerplate to make a class comparable.
Testing the constructor of Username requires us to create three different test methods as in listing 2. One for nullability because a different exception type is raised, the other one is for non-null but invalid inputs, and finally for the valid inputs because we need to make sure that it recognizes valid inputs as valid also.
Listing 2 Tests for Username class
Had we enabled nullable references for the project Username class was in, we wouldn’t need to write tests for the null case at all. The only exception to this is when writing a public API, which may not run against a nullable-references-aware code. In that case, you still need to check against nulls.
Similarly, declaring Username as a struct when suitable makes it a value type, which also removes the requirement for a null check. Using correct types and correct structures for types helps you reducing number of tests. The compiler ensures the correctness of our code instead.
Using specific types for our purposes reduces the need for tests. When your registration function receives a Username instead of a string, you don’t need to check if registration function validates its arguments. Similarly, when your function receives a URL argument as a Uri class, you don’t need to check if your function processes the URL correctly anymore.
Eliminate range checks
You can use unsigned integer types to reduce the surface area of invalid input space. You can see unsigned versions of primitive integer types in table 1. There you can see the varieties of data types with their possible ranges which might be more suitable for your code. It’s also important that you keep in mind whether the type is directly compatible with int as it’s the go-to type of .NET for integers. You probably have already seen these types, but you might not have considered that they can save you from writing extra test cases. For example, if your function needs only positive values, then why bother with int and checking for negative values and throwing exceptions? Receive uint instead.
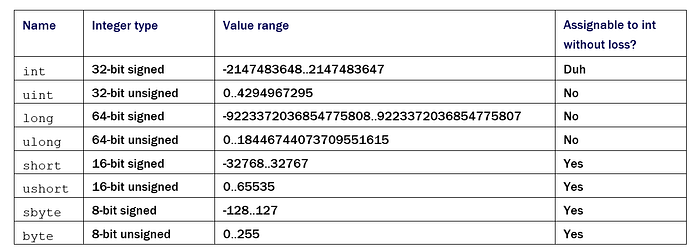
When you use an unsigned type, trying to pass a negative constant value to your function causes a compiler error. Passing a variable with a negative value is possible only with explicit type casting which makes you think about if your value is suitable for that function at the call site. It’s not the function’s responsibility to validate for negative arguments anymore. Assume that a function needs to return trending tags in your microblogging web site up to only specified number of tags. It receives a number of items to retrieve rows of posts as in listing 3.
In listing 3, we have a GetTrendingTags function which returns items by taking the number of items into account. Notice that the input value is a byte instead of int, because we don’t have any use case more than 255 items in trending tag list. This immediately eliminates the cases where an input value can be negative or too large. We don’t even need to validate the input anymore. One fewer test case and a much better range of input values, which reduces the area for bugs immediately.
Listing 3 Receive posts only belonging a certain page
#A We chose byte instead of int.
#B A byte or a ushort can be passed as safely as int too.
Two things are happening here; first, we chose a smaller data type for our use case. We don’t intend to support billions of rows in a trending tag box. We don’t even know what that looks like. We narrowed down our input space. Second, we chose byte, an unsigned type, which is impossible to become negative. This way, we avoid a possible test case and a potential problem that might cause an exception. LINQ’s Take function doesn’t throw an exception with a List, but it can when it gets translated to a query for a database like Microsoft SQL Server. By changing the type, we avoided those cases, and we don’t need to write tests for them.
Note that .NET uses int as the de facto standard type for many operations like indexing and counting. Opting for a different type might have to be cast and converted into int if you happen to interact with standard .NET components with that type. You need to make sure that you’re not digging yourself into a hole. For example, if you need more than 255 items in the future, you’ll have to replace all references to bytes with shorts or ints which can be a time-consuming task. You need to make sure that you are saving yourself from writing tests for a worthy cause. You might even find writing additional tests more favorable in many cases rather than dealing with different types. In the end, it’s only your comfort and your time that matters despite how powerful types are for hinting at valid value ranges.
Eliminate valid value checks
Sometimes we use values to signify an operation in a function. A common example is fopen function in C programming language. It takes a second string parameter that symbolizes the open mode, which can mean “open for reading”, “open for appending”, “open for writing”, and like this.
.NET team, decades after C has made a better decision and created separate functions for them. You have File.Create, File.OpenRead, File.OpenWrite methods separately, avoiding the need for an extra parameter and the need for parsing that parameter. It’s impossible to pass along the wrong parameter. It’s impossible for functions to have bugs in parameter parsing because there’s no parameter.
It’s common to use such values to signify a type of operation. You should consider separating them into distinct functions instead, which can both convey the intent better, and reduce your test surface.
One of the common ways in C# is to use Boolean parameters to change the logic of the running function. An example is to have a sorting option in our trending tags retrieval function as in listing 4, because, assume that we need trending tags in our tag management page too, and it’s better to show them sorted by title there. In contradiction with laws of thermodynamics, developers tend to constantly lose entropy. They always try to make the change with the least entropy, without thinking that how much burden it will be in the future. The first instinct of a developer can be to add a Boolean parameter and be done with it.
Listing 4 Boolean parameters
#A Newly added parameter
#B Newly introduced conditional
The problem is, if we keep adding Booleans like this, it can get complicated because of the combinations of those variables. Let’s say another feature required trending tags from yesterday. We add that to other parameters in listing 5. Now, our function needs to support combinations of sortByTitle and yesterdaysTags too.
Listing 5 More Boolean parameters
#A More parameters!
#B More conditionals!
An ongoing trend is our function’s complexity increases with every Boolean parameter. Although we have three different use cases, we have four flavors of the function. With every added Boolean parameter we create fictional versions of the function that no one uses, yet someone might try and get into a bind. A better approach to have a separate function for each client, as in listing 6.
Listing 6 Separate functions
#A We separate functionality by function names instead of parameters.
We now have one less test case and you get slightly increased performance for free as a bonus. The gains are miniscule and unnoticeable for a single function, but at points where the code needs to scale, they can make a difference without you even knowing. The savings increase exponentially when you avoid trying to pass state in parameters and use functions as much as possible. You might still be irked by repetitive code, which can easily be refactored into common functions as in listing 7.
Listing 7 Separate functions with common logic refactored out
#A Common functionality
Our savings aren’t impressive here, but such refactors can make greater differences in other cases. The important takeaway is to use refactoring to avoid code repetition and combinatorial hell.
The same technique can be used with enum parameters which are used to dictate a certain operation to a function. Use separate functions, and you can even use function composition, instead of passing along shopping list of parameters.
If you want to learn more about the book, check it out on Manning’s liveBook platform here.
